ogp-createrを形態要素解析を使用するようにupdateした
Yuto Nakamura / 2023/06/04 (1173 Words, 7 Minutes)
一ヶ月くらい前にこのブログを作ったとほぼ同時に、OGP画像を自動生成するRustアプリを作ったのですが、とある問題が生じました。画像にはその記事のタイトルが表示されるのですが、タイトルが変なところで区切られてしまうのです。
https://yutyan.dev/ogp-creater-rust
例えば以下の画像だったら、virtは区切らないで欲しいし、サイボウズ・ラボユースは区切らないで欲しいという感じです。

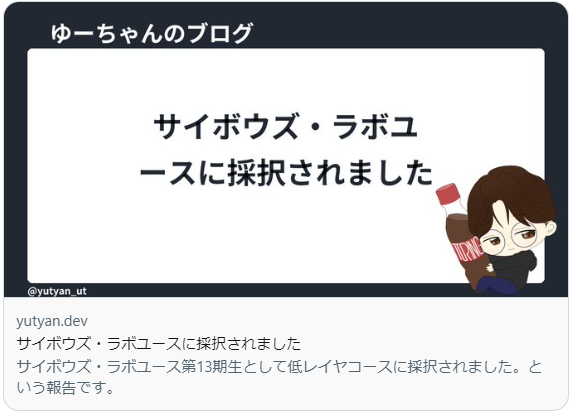
これまでのタイトル分割アルゴリズムは、文字列を1列に並べたときに、文字のscaleが70より小さくなるならちょうど文字列の半分で区切って2行に分けた上で配置するというものでした。これでは当然単語が区切られる問題が発生してしまいます。そこで、形態要素解析を利用して、単語の区切れ目を検出するようにしました。実装は例によってGitHubで公開しています。
https://github.com/yutyan0119/ogp-creater
最後に、OGP画像を生成するActionsにおいて、バイナリファイルをブログリポジトリに紐付けられたものではなく、ogp-createrの最新のreleaseから取得するように変更しました。これにより、ogp-createrの更新を行ったときに、ブログリポジトリのバイナリ更新を行わなくても、最新のogp-createrを使用することができるようになりました。
使用する形態要素解析
形態要素解析とは、文章を形態素という最小単位に分割することです。義務教育でよくやらされるこれ以上分解出来ないものに文章を分割しなさいというやつです。さらに、形態要素解析ではその単語の品詞も判定します。今回は品詞は使用しません。
日本語の形態要素解析といえば、Mecabが超有名ですが、最近の検索エンジンで使用されているのはKuromojiという形態要素解析器のようです。これを使用したRustのクレートがLinderaです。Linderaは元々kuromoji-rsを引き継いだものらしいです。1
他にもyoin等のプロジェクトが見つかったのですが、これが1番安定して使用できそうということで、Linderaを使用することにしました。使用方法はREADMEにも書いてありますが、以下のように非常に簡単です。
use lindera_core::{mode::Mode, LinderaResult};
use lindera_dictionary::{DictionaryConfig, DictionaryKind};
use lindera_tokenizer::tokenizer::{Tokenizer, TokenizerConfig};
fn main() -> LinderaResult<()> {
let dictionary = DictionaryConfig {
kind: Some(DictionaryKind::IPADIC),
path: None,
};
let config = TokenizerConfig {
dictionary,
user_dictionary: None,
mode: Mode::Normal,
};
// create tokenizer
let tokenizer = Tokenizer::from_config(config)?;
// tokenize the text
let tokens = tokenizer.tokenize("関西国際空港限定トートバッグ")?;
// output the tokens
for token in tokens {
println!("{}", token.text);
}
Ok(())
}
これを使用して、タイトル文を分割することにしました。
タイトル分割アルゴリズムの再考
先にも述べたように、これまでのタイトル分割アルゴリズムは、文字列を1列に並べたときに、文字のscaleが70より小さくなるならちょうど文字列の半分で区切って2行に分けた上で配置するというものでした。これには1つ利点があり、文字のスケールを臨機応変に変更できるという利点があります。
今回のアルゴリズムではスケールを固定にすることにし、文字列の行数を制限しないことにしました。文字の大きさ的に4行か5行くらいが限界ですが、まぁ良いでしょう。今回のアルゴリズムは以下のようにしました。
- 文字列を単語で区切る
- 区切った単語を指定した文字サイズで並べていき、指定した幅が超えないように行を構成することを繰り返す
- 各行の文字列を適切に配置する
1と2はsplit_stringという関数の中で行うようにしました。
fn split_string(
text: &str,
target_width: f32,
font: &Font,
default_scale: Scale,
) -> LinderaResult<Vec<String>> {
let dictionary: DictionaryConfig = DictionaryConfig {
kind: Some(DictionaryKind::IPADIC),
path: None,
};
let config: TokenizerConfig = TokenizerConfig {
dictionary,
user_dictionary: None,
mode: Mode::Normal,
};
let tokenizer: Tokenizer = Tokenizer::from_config(config)?;
let tokens: Vec<lindera_tokenizer::token::Token> = tokenizer.tokenize(text)?; //ここで形態素解析
let mut lines = Vec::new();
let mut current_line = String::new();
let mut current_width = 0.0;
//単語ごとに幅を計算しながら行を構成する
for token in tokens {
let word = token.text;
let word_width: f32 = word
.chars()
.map(|c| {
font.glyph(c)
.scaled(default_scale)
.h_metrics()
.advance_width
})
.sum::<f32>();
if current_width + word_width <= target_width {
current_line.push_str(word);
current_width += word_width;
} else {
lines.push(current_line);
current_line = word.to_string();
current_width = word_width;
}
}
lines.push(current_line); // Add the last line
Ok(lines)
}
この関数からの返り値のlinesを使用して、各行を実際に画像に配置する関数が以下です。
fn draw_centered_lines(
image: &mut ImageBuffer<Rgba<u8>, Vec<u8>>,
font: &Font,
lines: &[String],
color: Rgba<u8>,
scale: Scale,
) {
let v_metrics: rusttype::VMetrics = font.v_metrics(scale);
let line_height: f32 = v_metrics.ascent - v_metrics.descent + v_metrics.line_gap;
let text_height: f32 = line_height * lines.len() as f32;
let start_y: f32 = (image.height() as f32 - text_height) / 2.0;
for (i, line) in lines.iter().enumerate() {
let text_width: f32 = line
.chars()
.map(|c| font.glyph(c).scaled(scale).h_metrics().advance_width)
.sum::<f32>();
let start_x: f32 = (image.width() as f32 - text_width) / 2.0;
let y_position: f32 = start_y + line_height * i as f32;
draw_text_mut(
image,
color,
start_x as i32,
y_position as i32,
scale,
&font,
line,
);
}
}
これでいい感じに単語で区切った画像が作れるようになりました。以下のように、virtもサイボウズ・ラボユースも途中で区切られません。
でHello-world!.png)

GitHub Actionsを変更する
これまではこのブログを管理しているリポジトリにogp-createrのバイナリを直接配置し、Actionsの中ではそれを使用するようにしていました。しかしながら、今回形態要素解析を導入したことにより、バイナリのサイズが辞書データを含み、約80MBと、Gitで管理するには相応しくないサイズになってしまいました。そこで、バイナリを直接管理するのを辞めることにしました。
この場合の方針は2つです。
- このブログのGitHub Actionsの中で、ogp-createrのソースコードをビルドして使用する
- 変更するのはこのブログのリポジトリのActionsのみ
- ogp-createrのソースコードをビルドしたバイナリを別のリポジトリに配置し、そこからダウンロードして使用する
- 変更するのはこのブログのリポジトリのActions及び、ogp-createrのリポジトリのActions
最初は前者で実装していたのですが、ブログの更新頻度 » ogp-createrの更新頻度であるため、逐一ビルドするのは時間が勿体ないと感じ、後者に変更しました。
バイナリをビルドしてreleaseに配置するようにする
まずは、バイナリをビルドして、releaseに配置するようにしました。tagがpushされたときに、リポジトリをcheckoutし、ビルドし、releaseを作成し、releaseにバイナリをアップロードするようにしました。以下がそのコードです。
name: Build and Release
on:
push:
tags:
- '*'
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Install Rust
uses: actions-rs/toolchain@v1
with:
toolchain: stable
override: true
- name: Build
uses: actions-rs/cargo@v1
with:
command: build
args: --release
- name: Create Release
id: create_release
uses: actions/create-release@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
tag_name: ${{ github.ref }}
release_name: Release ${{ github.ref }}
draft: false
prerelease: false
- name: Upload Release Asset
id: upload-release-asset
uses: actions/upload-release-asset@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
upload_url: ${{ steps.create_release.outputs.upload_url }}
asset_path: ./target/release/ogp-creater
asset_name: ogp-creater
asset_content_type: application/octet-stream
これで、releaseにバイナリが配置されるようになりました。

リポジトリをcheckoutしてバイナリをダウンロードして、使用するようにする
リポジトリ名さえわかっていれば、最新のreleaseのdownloadは以下のように行えます。
curl -sL https://github.com/yutyan0119/ogp-creater/releases/latest/download/ogp-creater -o ogp-creater
これを利用します。
name: OGP Image Generator
on:
push:
branches:
- master
- change_workflow
paths:
- '_posts/**/*.md'
- '.github/scripts/ogp_gen.py'
- '.github/workflows/ogp_image_gen.yml'
jobs:
generate_ogp_image:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v2
- name: Download ogp-creater
run: |
curl -sL https://github.com/yutyan0119/ogp-creater/releases/latest/download/ogp-creater -o ogp-creater
chmod +x ogp-creater
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.8
- name: Generate OGP Image and Update Markdown
run: python .github/scripts/ogp_gen.py
- name: Commit and push changes
run: |
git config --local user.email "78634880+yutyan0119@users.noreply.github.com"
git config --local user.name "yutyan0119"
git add assets/images/ogp_image/* _posts/**/*.md
git diff --quiet && git diff --staged --quiet || git commit -m "Automatically generated OGP images"
git push
簡単ですね。他の変更点として、最後にgit add .していたのを、バイナリをcommitしないように、ogp画像のディレクトリと変更されたmarkdownに限定するようになりました。また、実行するPythonスクリプトのバイナリへのパスを変更しています。
まとめ
ogp-createrの文字列分割アルゴリズムを変更し、自然なOGP画像が生成されるようになりました。同時に、各種GitHubActionsを変更し、ogp-createrのバイナリをダウンロードして使用するようにしました。これにより、リポジトリにogp-createrのバイナリが不要になった他、ビルドする時間も省けるようになりました。